June 8, 2026
Make It Whole: Porting AniGen to Apple Silicon
Or how I made T-Rex run on Apple Silicon

The official banner of AniGen repo
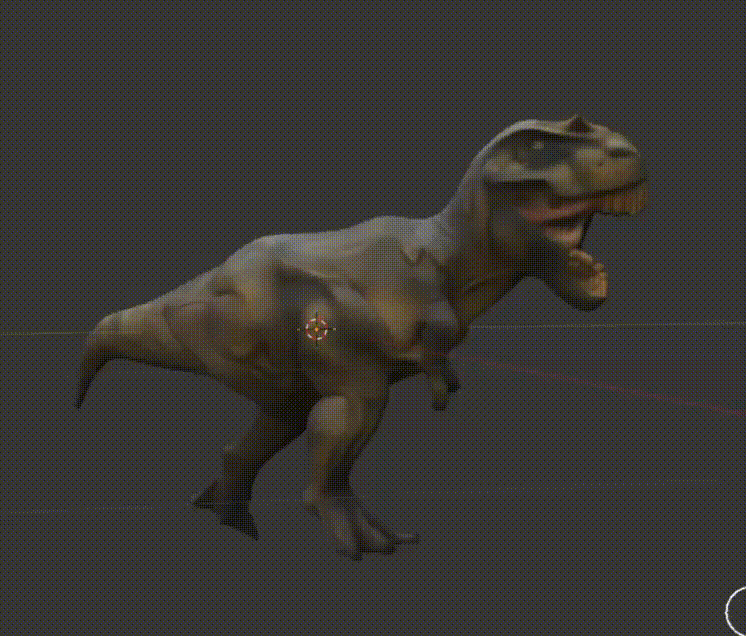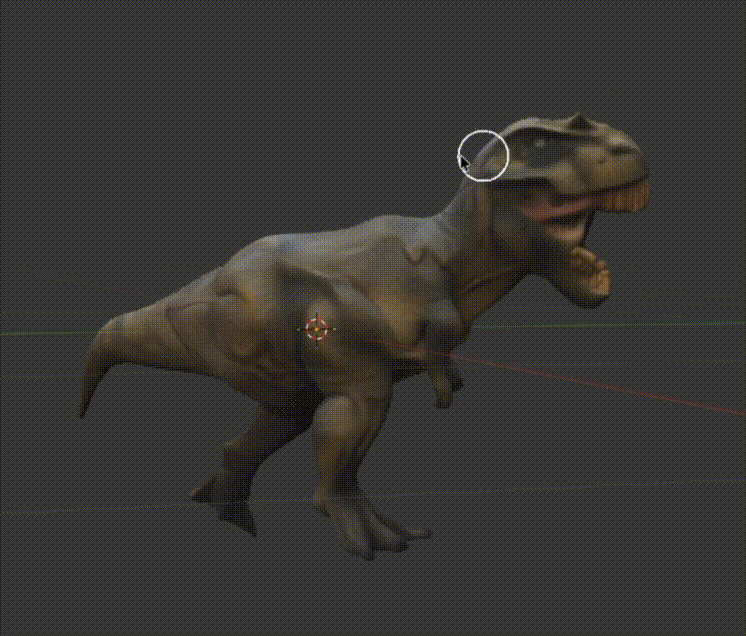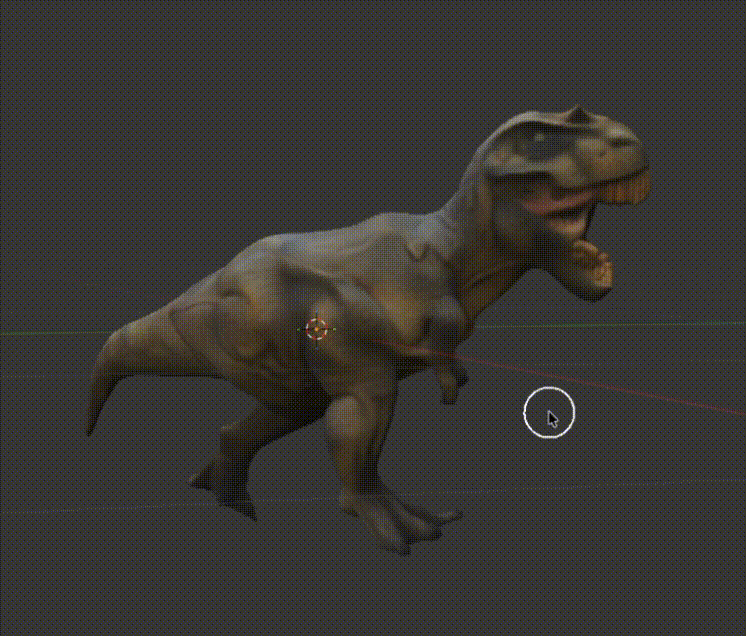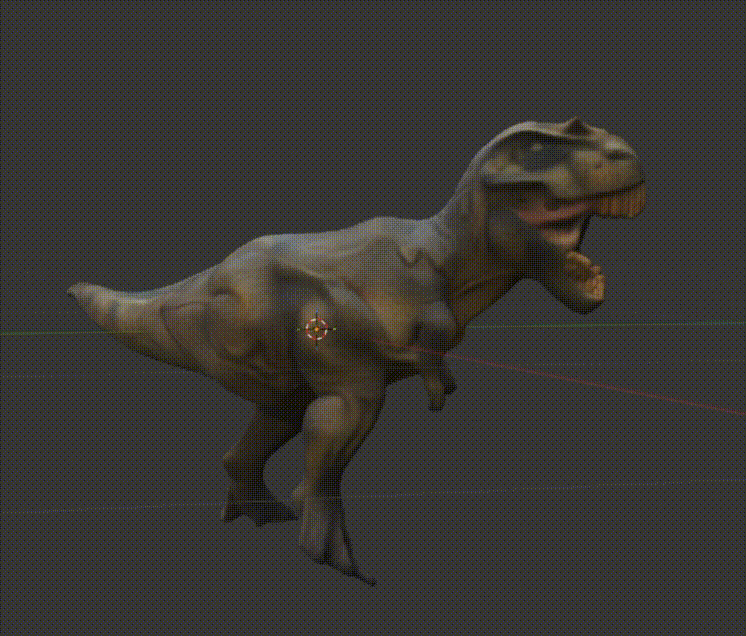
Look at him go! (I have no idea what I'm doing with animation)
Third in the porting series. First I taught my Mac to render Pixal3D, then I taught it to sing. Now I wanted the model that gives skeletons and skin weights to things.
AniGen takes a single image and gives you back a fully rigged, animate-ready 3D asset: a coherent mesh, an articulated skeleton, and skinning weights, all from one PNG. Captivating as ever. It is also, per its own README, Linux + NVIDIA CUDA only.
You know where this is going.
In the beginning there was an idea
But you see, in the beginning I had slightly different idea. I figured that whatever AniGen uses for 3D model generation could be switched for Pixal3D - obviously this would be match made in heaven. The best 3D model generator + rigging + weight skins would amount to an awesome tool for local animation or gamedev (or so I think). Unfortunately it quickly turned out that all of these things are intertwined and trained together, which meant that it was not really possible (at least in any somewhat easy way). So, I pivoted. To just porting it as it is, and this was supposed to be the easy one. I'd already done Pixal3D and AniGen seemed to be using mostly similar stack. I had the Metal toolkit sitting right there in - flex_gemm to stand in for spconv, mtldiffrast for nvdiffrast, mtlbvh and mtlmesh for the CUDA mesh (cumesh) ops. The plan was basically "point AniGen at the parts I already wrote, watch a dinosaur come out, go to bed."
The plan survived contact with reality for about four minutes.
Here's a thing nobody says about CUDA: apparently it's pretty forgiving. It silently tolerates sloppy dtypes, out-of-bounds indexing, the occasional divide-by-zero (okay, it's not exactly that, but you know, drama). It shrugs and gives you a number. Metal does not shrug. Metal either errors loudly, or - my favorite - hangs the GPU command buffer at 0% CPU and waits for you to understand the depth of your sins.
Ten ways to crash before breakfast
Getting the pipeline to run end to end took ten fixes, each one a different CUDA-ism failing in a different stage. I'll spare you all ten. Here are the ones that taught me something.
The .max(dim) hang. A sparse conv computed coords[:, 1:].max(0) on MPS integer coordinates and the Metal command buffer just stopped. 0% CPU and no error. The annoying thing is that it kept GPU pegged at 100% even after killing the host python process or even killing entire WindowServer, because the stuck code was on levels inaccessible for me and thus I had to restart my Mac couple of times before figuring out the reason. The fix was coords[:, 1:].cpu().amax(0) — do the reduction on the CPU and stop asking Metal to argmax integers.
The one that bricked my GPU. This one reminded me of Pixal3D. The sparse-conv layer cached its neighbor map keyed by kernel size only. When the network upsampled from a coarse resolution (1,949 active voxels) to a fine one (8,088), SparseUpsample copied the parent's cache wholesale — so a neighbor map built for 1,949 points got reused for a conv over 8,088 points. Out-of-bounds GPU indexing. Command buffer wedges. WindowServer watchdog fires. Kernel panic. Full reboot.
The clue was in a crash log: an error referencing mask[52623], where 52623 is exactly 1949 × 27. The coarse neighbor map, 27 taps per point, leaking onto the fine layer. The fix was one line - key the cache by coordinate identity, not kernel size.
The rest were variations on a theme: uint32 promotion that MPS refuses and CUDA does silently; a float64 tensor that fails the move to MPS before the .float() that would have saved it (reorder to .float().to(dev)); fp16 activations meeting fp32 weights because my upcast only recursed one level deep; hardcoded .cuda() calls that needed a permanent redirect shim. Death by a thousand papercuts, each one a CUDA assumption I had to find and unravel.
And then, after ten fixes, it ran. SS flow → SLAT flow → VAE decode → FlexiCubes → skin transfer → texture bake → GLB export. A mesh.glb fell out the other end. I opened it.
It was a T-Rex.

Problem was that it was made of 1,779 pieces of confetti.
The confetti
So, a dinosaur-shaped cloud. The layout was right - there was a body, there were legs, there was a tail, all sitting roughly where a T-Rex's body, legs, and tail should sit. But there was no surface. 1,779 disconnected components, the largest a heroic 32 faces, scattered in the silhouette of an animal. The coarse structure was clearly correct and the fine surface had simply… shattered like a broken glass. Every voxel emitted its own little isolated patch instead of stitching into a manifold.
I'd seen similar failures in the Pixal3D port - there it was an mtlbvh stack overflow corrupting a distance field. I did not know the cause, because AniGen extracts its mesh with FlexiCubes, a completely different path.
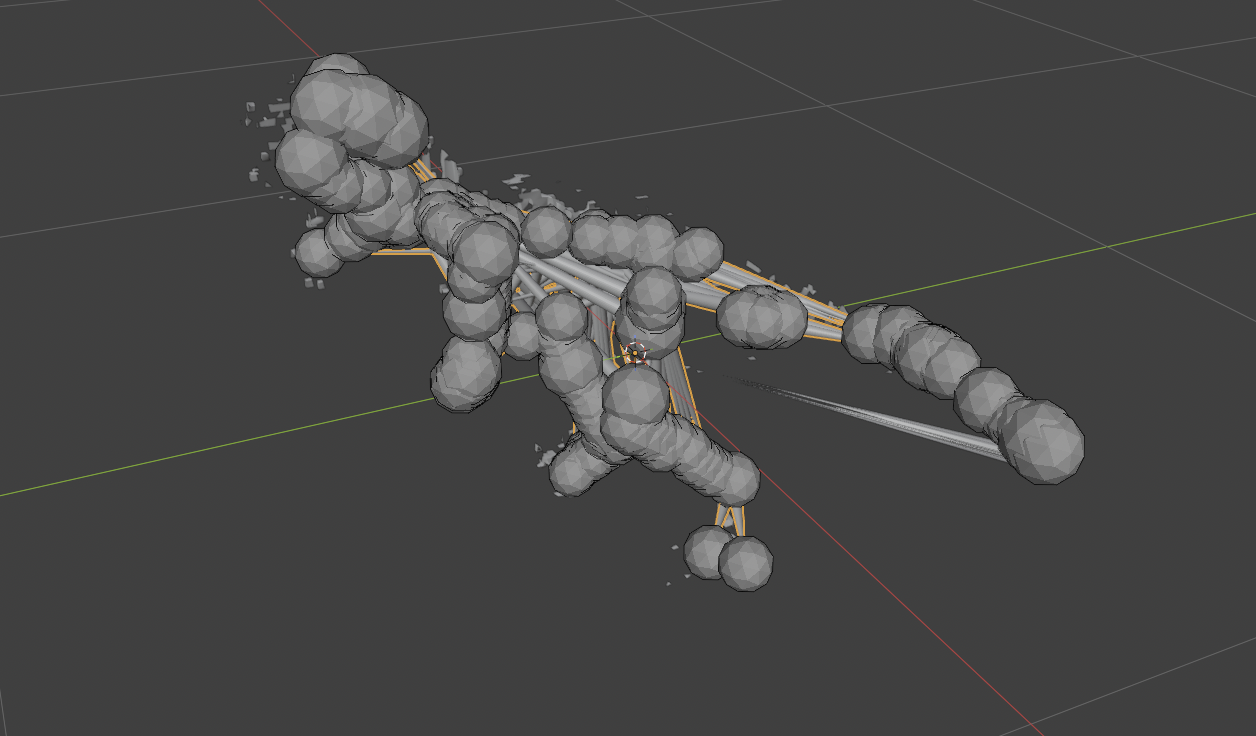
It even seemed to have roughly correct skeleton
Session 1 ended there, with a dinosaur made of static and a note to myself: this is the open problem. I had ruled out a few suspects - the conv forward pass matched a reference 7/7, torch.unique round-tripped correctly on MPS - but I had no CUDA box to diff against, and you cannot debug a numerical divergence you can't compare to anything. I went to bed annoyed.
Another port, another rental
There is a certain kind of irony in constantly renting Nvidia cards for the sole purpose of avoiding them, and yet I think it's fair to assume that it will happen again in the future if I choose to still port these things.
Of course, it's the right move, and here's why: a confetti mesh is a numerical divergence somewhere deep in a twelve-block decoder, and the only way to localize it is to run the identical latent through both devices and binary-search for the first tensor that disagrees. So I dumped a single 947KB latent from the Mac, rented a 3090 on vast.ai, built a matched Python 3.10 + CUDA 12.1 environment, and decoded the exact same latent on real silicon.
CUDA's verdict: 4 components, one 481,540-face body. Clean. A whole dinosaur, not of the confetti variety.
That meant the latent part was fine and the bug had been hidden definitively in the Mac decode. Now I just had to find where exactly. I captured the CUDA intermediates - every block output, both upsample layers, the final layer, plus coordinates to align by - 363MB of reference tensors, and diffed them against the Mac, block by block, aligned point-for-point.
Blocks 0 through 11: identical to four significant figures. Which, as a bonus, exonerated the one suspect I'd been side-eyeing the whole time - my hand-rolled naive attention. If that fp32 fallback were subtly wrong it would have drifted the block outputs, and they matched to four figures. The bug I saw coming really was the bug I'd already killed. The actual culprit was somewhere I hadn't thought to look at all. Then upsample.0 - the first subdivide block - diverged hard. Mean magnitude 2.56 on the Mac versus 4.13 on CUDA. Found the floor it was on. Now the room.
I hooked the children of upsample.0. The subdivide itself was fine (coordinates matched, so the structure was right). But out_layers.0, a 3×3×3 conv, came out at mean 0.19 versus CUDA's 7.45. And out_layers.3, a zero-initialized conv, came out at exactly 0.0.
Exactly zero. Noise from one conv, dead zero from another. Those convs are running at their initialization values. The weights never loaded.
And here's the plot twist I did not see coming. I came into this port braced for another cursed kernel. The Pixal3D post was a kernel horror story. So I checked the Metal math first - built the neighbor map on the real coordinates (every point had its 8–27 neighbors, not empty), checked the im2col gather (matched CPU exactly), checked the addmm with its 20,736-deep contraction (matched exactly).
The kernels were innocent. The Metal math was perfect. The bug was upstream of the math entirely, in the least glamorous code in the entire repository: load_state_dict.
Bug A: strict=False, the silent assassin
The decoder loads its weights with strict=False. You know, the friendly option. The one that doesn't make a fuss.
It was dropping 24 weight tensors on the floor without a word.
The checkpoint, trained with the CUDA spconv library, stores conv weights under keys like out_layers.0.conv.weight - because spconv's SparseConv3d nests the actual kernel one level down in self.conv. My flex_gemm drop-in stores it directly as self.weight. So every single conv key in the checkpoint missed its target by one .conv. segment, strict=False swallowed the mismatch politely, and 24 convolutions ran the entire decode at their randomly-initialized values.
strict=False is the option that turns "your weights are wrong" into "your dinosaur is slightly confetti." Twenty-four missing keys, twenty-four unexpected keys, zero exceptions raised. I added a key remap in _load_from_state_dict - <prefix>conv.weight → <prefix>weight - and watched the 3×3×3 convs snap into agreement with CUDA at half a percent.
Half a percent. Not zero. Because there was a second bug hiding behind the first.
Bug B: the transpose that only matters when it doesn't
After Bug A, the 3×3×3 convs matched - but the 1×1 skip-connection convs were still off by 118%, even though their weights now loaded perfectly. The weight tensor was byte-identical to the checkpoint. flex_gemm computed feats @ W.view(Co, Ci).T exactly correctly. And the answer was still wrong.
This one I had to solve with least-squares. I took CUDA's own input and output for that layer and asked: what weight layout actually maps one to the other? The answer came back cout == feats @ W.reshape(Ci, Co) - residual 4e-4. Not (Co, Ci).T. The other order.
Turns out spconv special-cases 1×1×1 convolutions as a plain GEMM and stores that weight in (Ci, Co) order - transposed relative to every other conv in the network. It's a performance optimization that's completely invisible until you're hand-porting the weight loader on a different framework, at which point it costs you an afternoon and your faith in matrix dimensions.
The whole Bug B drama was: is the saved weight grid stored rows-then-columns (Co, Ci) or columns-then-rows (Ci, Co)? spconv secretly stored the 1×1 ones the other way around ((Ci, Co)), so my Mac was reading "the recipe for output channel 5" out of what was actually "the recipe involving input channel 5" — channels crossed, garbage out.
Fix: gate on kernel_size == (1,1,1), transpose Co and Ci, move on with your life.
And when the confetti settled
Both fixes in, same latent, Mac versus CUDA:
Raw SDF field: fraction-below-zero 0.2976 on the Mac, 0.298 on CUDA.
Mesh: a 481,396-face body on the Mac, 481,540 on CUDA.
Bit-for-bit, to within floating-point noise. The component count walked down the whole way: 1,779 → [Bug A] 1,002 → [Bug B] one coherent, textured T-Rex.
The villain of this port was not a Metal kernel. It was strict=False and a framework's idea of a clever GEMM.
The spike and the dust
The dinosaur was whole, but it had a spike - a thin sliver shooting off the tail tip - and a faint halo of dust specks around it. Annoying. Cosmetic. The kind of thing you could almost ship and hate yourself for.

I dumped the raw decode before postprocessing. It was one clean 457,000-face body plus eight single-triangle specks. So the spike was not in the geometry - it was being manufactured by the postprocessing pass. Specifically: 76 faces had a longest edge of ~0.45, roughly half the bounding box, against a median edge of 0.0044. Degenerate slivers, bridging clear across the mesh, rendering as a spike.
The source was FlexiCubes._linear_interp. When the signed distance field values at the two ends of an edge are nearly equal, the zero-crossing computation has a denominator approaching zero - and instead of landing on the edge, the interpolated vertex extrapolates far outside it. CUDA almost never hits exact-enough equality to trigger it. MPS, with its particular fp32 rounding, hits it just often enough to grow a tail spike. You can't re-weight your way out of bad geometry; you remove it at the source. Drop faces whose longest edge exceeds 10× the median, drop components smaller than 1% of the largest, let the existing hole-filler close the seams. Max edge 0.45 → 0.056, one connected body, dust gone.

Look at this glorious dude
The texture bake I'd written off
Back in Session 1 I'd recorded a defeat: the high-quality opt texture bake - the differentiable one that backprops through the renderer for 500 Adam steps - hard-crashed with a SIGTRAP on MPS. Exit 133. I'd forced the cheaper projective fast bake and moved on, filing it under "mtldiffrast backward doesn't work on Metal."
That story was wrong, and I want to be honest about being wrong, because the wrong story cost me a feature for two sessions. When I actually re-tested, plain dr.texture backward worked fine. The crash only reproduced in one specific path: the mip-mapped gradient kernel, at 1024² texture resolution. The opt loop was passing UV derivatives purely for mip anti-aliasing - and at the resolution I was baking, the UV footprint is about one texel per pixel, so the mip path was numerically pointless anyway. Gate the mip on torch.cuda.is_available(), call plain bilinear on MPS, and the opt bake runs to completion. L1 loss to 0.005, no abort.
(It looks about the same as the fast bake here, because the real fidelity ceiling turned out to be the decoder's per-vertex colors, not the texture resolution. But it runs now, and "I was wrong about why it crashed" is a more useful sentence than "it can't be done.")
Make it move!
A rigged mesh that doesn't animate is just a mesh with extra steps. So I imported the T-Rex into Blender and drove it with the MCP bridge to find out.
Skinning parity: solid. 57 bones, 57 vertex groups, every name matching, 100% of 25,469 vertices weighted, the armature modifier bound and deforming cleanly under motion. The port had carried the rig across intact.
And then the jaw tore. Under animation, the snout stretched in a way no dinosaur's should.


Yeah, I think your teeth are fine sir!
I assumed a weight bug - my bug, a Mac regression - and went hunting. I was wrong again, and this time being wrong taught me something about AniGen itself rather than about Metal. The generated skeleton had three disconnected components: a 53-bone body, and two stray, unparented bones sitting in the head. Pose evaluation can't propagate motion into a bone with no parent, so when the head moved, those two bones stayed frozen - and the skin weighted to them tore. This wasn't a porting artifact at all; it reproduced perfectly on the CUDA ground truth. AniGen just sometimes emits disconnected rigs.
So I built a fix that vanilla AniGen doesn't have: union-find the parent forest, keep the largest component as the body, and reparent every orphan root to the nearest body joint. Attaching an orphan to a different component can't create a cycle, and skinning is keyed by bone name so the weights don't care. The per-vertex tearing dropped from 0.062 to 0.0099 - six times better - and the reconnected T-Rex now animates its head with no stretch. A value-add I only found because the Mac made me look closely at something the CUDA path quietly ships broken.
When the confetti settled, for real this time
So: the Mac now takes one image of a T-Rex and produces a coherent, textured, animate-ready rigged dinosaur. The decoder matches CUDA bit-for-bit. The mesh is one clean body. The skeleton is one connected tree - arguably cleaner than what the reference path produces. And it runs in about three and a half minutes on an M-series GPU. I'd call that a win.
Number of custom Metal kernels I had to write for this port: zero. Every kernel I needed already existed from Pixal3D. The entire AniGen port came down to a stale cache key, a swallowed strict=False, one transposed weight layout, a sliver filter, a mis-scoped crash, and a disconnected skeleton.
Next stop: PiD (a cool upscaler decoder) from Nvidia themselves :D