May 30, 2026
The Long Walk to Apple Silicon: Porting Pixal3D, One Cursed Kernel at a Time
Or: how a single device const ulong* versus device atomic_ulong* cost me two weeks of my life, and I'd do it again.

TL;DR: I ported Pixal3D inference pipeline over to Apple Silicon. Here's the link: https://github.com/pawel-mazurkiewicz/Pixal3D-mac/tree/master
The beginning (it sounded easy)
I've discovered Pixal3D when casually browsing HuggingFace about two days after it had released (it actually released on my birthday, May 12 :D). It looked exciting as hell! Last 3D model generator that I tried and was local was actually TRELLIS2 in its ported form by shivampkumar (https://github.com/shivampkumar/trellis-mac). Unfortunately I quickly found out outputs to be disappointing - alpha blending was off - the mesh was translucent at certain angles, there were some missing faces (we'll hear more about that) and the overall quality was off. The other one I'd tried would be Hunyuan3D 2.1 (they sadly stopped releasing weights after 2.1), but it didn't work for me at all in ComfyUI on M5 Max and it was also old news by then and as we know the world of AI is moving very fast. I am also very interested in the 3D model generation - you see, I'm developing a game. A game that I consciously decided to be built a lot with AI help in various ways, an experiment of sorts. So this is acutely relevant to my interests.
Pixal3D is gloriously modern image-to-3D models - you hand it a single PNG of, say, a fairy house, and it hands you back a textured GLB you can spin around in any glTF viewer. It was released early May by TencentARC and is currently one of the best 3D model AI generators out there - at least when it comes to open weights. It descends from the TRELLIS family (although started out on Direct3D-S2), and like most of that lineage it was born, raised, and lovingly optimized on NVIDIA CUDA.
Of course I was very disappointed to see that Pixal3D was CUDA dependant. And CUDA dependant hard - it requires nvidiffrast, cumesh, libnatten (compiled for specific NVidia arch), cubvh - basically full stack was for GPUs that understood CUDA. This made me slightly upset, but I thought to myself - why shouldn't I try to get it working on my Mac? I mean, everything I needed seemingly was open source and because of that TRELLIS2 port Shivam Kumar did and the work of Pedro Naugusto, who seemingly ported all of these hard CUDA requirements to Metal, armed with AI this looked like a fun, one or two evenings project.
Oh boy was I mistaken.
It bears noting, that I was very ignorant of the internals of computer graphics, the math behind it and also the Python + CUDA ecosystem. Basically a clueless fool. But I was very determined to get this working on my computer. It only made sense! When you don't want to pay yet another service for their "credits" it turns out it's a very effective motivation. I lost some sleep, but I didn't lose my drive. I have even entertained an idea of accelerating things with Apple Neural Engine (ANE) and CoreML
The plan was simple though:
1. Swap
cudaformpsin a few.to(device)calls.2. Maybe recompile a couple of custom CUDA kernels into Metal.
3. Generate a fairy house.
4. Brag on the internet.
I mean, I've been running local LLMs for years at this point, how hard could that be, right? ...RIGHT?

Reader, to get to step 4 it took me two weeks of obsessive work.
Act 0: the texturing pipeline I lovingly built and then threw in the bin
The thing is that porting this deep generative pipeline was almost good soon enough with that plan. You know how they say that the 80% takes 20% of the time but that 20% takes 80% of the time? Yeah, it was like that here. Same model weights (byte-identical). Same seed. Same input image. And yet the Mac output looked... wrong. Shrunken. Desaturated. Geometry shredded, details lost. At first also without uv unwrapping and textures. Like someone had run that fairy house through a dryer on the hot cycle and then attacked it with a cheese grater.
Before any of the cursed-kernel detective work, there was a more innocent problem: the Mac couldn't texture a mesh
at all. The function that turns a raw mesh + voxel colors into a finished, UV-unwrapped, textured GLB - o_voxel.postprocess.to_glb - is CUDA-only. No CUDA, no texture. So the very first job wasn't fixing texturing; it was *inventing* it from parts I already had on the machine.
It was kind of a blast. The plan: skip the unportable native stack entirely and assemble a texturing pipeline out of Python, Blender, and sheer optimism. MacGyver kind of stuff - duct taping things until they worked.
Get a mesh out at all - a CPU fallback for the CUDA-only mesh extractor. It worked, but left a constellatio
n of pinprick holes wherever the iso-surface couldn't close a cell.Fill the holes - easy, right? Blender has a fill-holes operator. Except the GUI op routes through the undo stack and hung indefinitely on a 2.7M-face mesh. Dropped down to
bmesh.ops.holes_filldirectly. Fine. Moving on.UV unwrap - reach for xatlas, the obvious tool, which actually is a part of the original stack. xatlas took one look at a Pixal3D-density mesh and produced hundreds of sub-pixel charts over 30–60 minutes. Tuned its
max_costfrom 2.0 down to 1.0 to halve the wall-clock, then gave up and subprocessed into a headless Blender install (--background --factory-startup) to do the unwrap instead.Bake the color - a KDTree inverse-distance-weighted sampler, pulling voxel colors onto each rasterized texel. First run: a completely black texture. The IDW cutoff was a fixed world-space distance tuned for a 512³ grid; at Pixal3D's 1024³ it shrank to ~0.002 world units, and after decimation 99% of texels sat too far from any voxel to get a single non-zero weight. Fix: measure the cutoff in voxel units instead.
And then, because the universe enjoys these things, two bonus puzzles that had nothing to do with color and everything to do with "why does it look haunted":
The model came out inside-out and upside-down. The export rotation got fought twice - Pixal3D is natively Y-up, but the CUDA exporter quietly applies a Z-flip, and matching it meant also flipping face winding (a reflection has determinant −1; skip the winding flip andevery normal points inward, so the whole model vanishes under backface culling). I diagnosed the orientation by loading the GLB straight into Blender and eyeballing where the heavy mass sat.
The fairy house was an x-ray. After the rotation fix, the render looked transparent - towers visible only as silhouettes. The baked color was RGB, trimesh expanded it to RGBA with alpha = 0 in the empty gutter texels, and glTF viewers honored that as see-through even in OPAQUE mode. Forced alpha to 255, set
doubleSided = True, and the ghost solidified into a house.
It worked. It got a textured, correctly-oriented, opaque fairy house out of an Apple Silicon Mac. I was thrilled for about a day - right up until I put it next to the official reference output.
It looked nothing like it. The reference atlas is a dense mosaic of a thousand-plus tightly-packed UV islands filling a 4096² canvas (the genuine cumesh.uv_unwrap, doing real angle-clustered chart growing). Mine was six axis-aligned projection slabs covering maybe 20% of a 2048² canvas, the rest empty. The geometry was right, the orientation was right, the alpha was right - and the surface read as a grayscale smear with a few sparse hints of color.
The verdict in my notes is blunt: "they don't look ANYTHING alike … it's not usable in any shape or form."
So Act 0 ends with the pipeline I'd lovingly hand-built getting deleted. The lesson - the real answer was never
to reinvent texturing in Python, but to port the native cumesh + o_voxel Metal stack and make that run faithfully on the Mac. Which is exactly where the rest of this story lives: every bug below is a bug in that native stack. Sometimes the most productive thing you build first is the wrong thing, fully, so you finally understand why you needed the right one.
Act 1: standing on the shoulders of Pedro Naugusto
Here's the thing that made this whole project even thinkable: I didn't have to port the CUDA stack to Metal from scratch. Someone already had. A developer named Pedro Naugusto had taken essentially the entire hard-CUDA dependency tree and reimplemented it in Metal - cumesh became mtlmesh, cubvh became mtlbvh, nvdiffrast became mtldiffrast, flex_gemm became mtlgemm - plus a Mac-flavored o_voxel. This is the open-source dream, right? Someone in the world has already suffered so you don't have to.
So Act 1 was supposed to be the easy bit: throw away my Python-and-Blender duct tape, wire in Pedro's Metal kernels, and let the real to_glb pipeline do the geometry cleanup and UV unwrap the way CUDA does it. I bolted it on through a subprocess "bridge" (o_voxel_native_export.py) - a slightly cursed arrangement forced by the native wheels being built for Python 3.11 while the Pixal3D venv was 3.12, so the two halves literally couldn't share an interpreter and had to talk across a process boundary. (I'd eventually unify everything onto a single Python 3.10 venv and run it in-process, because I'm a silly goose that started out with Python 3.12, but that's a much later.)
And the first results were genuinely encouraging. Flipping the native Metal simplifier on (PIXAL3D_SIMPLIFY=metal) cut the wall-clock roughly in half - from 24:55 down to 12:19 - turning thirteen-and-a-half minutes of my hand-rolled Python post-processing into about 30 seconds of native Metal. Fast. Correct-ish. I started to believe step 4 (brag on the internet) was within reach.
It was not within reach.
Because when I loaded the output into Blender and - crucially - turned the camera inside the model, the truth showed up. CUDA produces a single sealed shell. Every Mac variant I could produce - my Python pamo port, the native Metal simplify, the full native chain - produced a sieve: a surface peppered with thousands of tiny holes. All the "jagged edges" and "missing triangles" and "floating shards" I'd been chasing from the outside were just the exterior view of those same holes. I hadn't been looking at a dozen different bugs. I'd been looking at one defect from a dozen angles.


Some of the things I had to fight against
And then the genuinely humbling part. My first theory was that Pedro's simplify.metal was missing a winding-flip-rejection check that the CUDA simplify.cu had - a plausible cause for collapsed, hole-punched geometry. I was confident enough to swap the whole simplify step back to my slower Python port to "fix" it. Then I had an AI agent do a careful line-by-line audit of the Metal against the CUDA, and... the check was right there. simplify.metal:56. Verbatim. Pedro's port was faithful (or almost faithful as it turned out, I'll get back to it). My entire patch was built on a misdiagnosis - I'd blamed someone else's correct code for my own pipeline's symptom. (I also took a side-quest into a community MLX-native port of the model around here - essentially similar effort to mine - hoping a they might have figured out something that I hadn't. It produced visibly worse output than what I'd already had. That wasn't a way out.)
So Act 1 ends with the stack fast, the geometry still a sieve, and me out of guesses. I'd been playing whack-a-mole with symptoms for several days and every fix just revealed another mole. The conclusion wrote itself: stop guessing where the bug is. Go measure where it is.
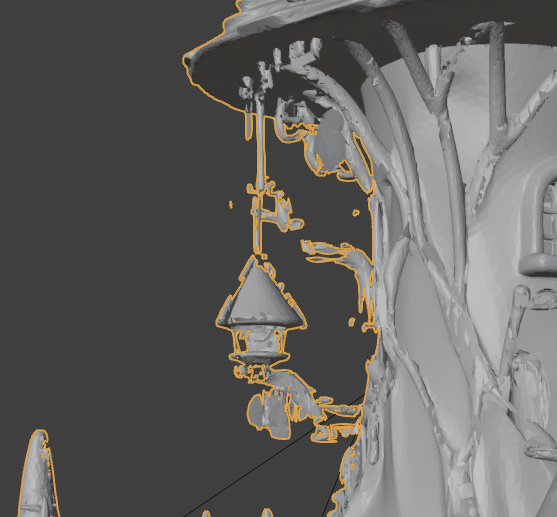
I've seen this lantern so many times by now...
Act 2: I rented an NVIDIA GPU to debug my Mac
Yes, I've resigned myself to renting a GPU to have data and approach this more "scientifically". I had to get "ground truth" - what I am actually working towards, you know? Like on m a t h e m a t h i c a l level.
sigh
You cannot debug a thing this big by squinting at it. So before fixing anything else, I built a divergence hunt harness - instrumentation (gated behind a PIXAL3D_DUMP_FIXTURES env var so it never touches production) that dumps the intermediate tensor at every pipeline stage boundary, on both backends. Then you diff the .pt files stage by stage:
The first stage that shows a non-trivial max-abs-diff is the bug boundary. Everything before it is reproducing CUDA correctly; everything after it is consequence, not cause.
The pipeline has clean seams - preprocessed image → camera params → sparse structure → shape latent → decoded mesh → texture latent → decoded texture → mesh extraction → to_glb. Find the first RED stage, and you've gone from "the whole thing is broken" to "this one subsystem is broken."
There was just one delicious problem with this plan: to get the reference tensors, I needed to run the pipeline on CUDA. Which I didn't have. So the punchline of this entire Mac-porting saga is that I ended up renting NVIDIA GPUs by the hour - vast.ai boxes, an SSH-plus-rsync harness to ship a test script up, run the capture, and pull the .pt fixtures back home. To debug Apple Silicon I had to keep crawling back to the very hardware I was trying to escape. About an hour for the first cold capture (conda, a ~15 GB weight download, one run), then 20–30 minutes per subsequent cycle. I made my peace with it. The irony was palpable.
And here I have to be honest about the timeline, because the divergence hunt was the back half of the story, not the front. Before I got disciplined, there were a lot of days of pure whack-a-mole on the geometry sieve - and a graveyard of beautiful theories that all turned out to be wrong. Was it a missing merge_vertices step? (Welding at 1e-5 dropped 42% of the verts and the mesh was still broken.) A too-tight fill_holes perimeter? (Loosening it traded holes for fan-triangulation "sunbursts" at every doorway - a metric win and a visual disaster.) Swap the simplifier for fast_simplification? pymeshlab? Bypass charts with a single whole-mesh xatlas.parametrize call? (That last one climbed to 64%, ate 22 GB of RAM, and never finished.) Every one of them: ❌.
The most expensive lesson of the whole graveyard was an anti-pattern in my own testing. Early on I "exonerated" the Mac cleanup chain by feeding it a clean CUDA mesh and watching it stay clean - proof the cleanup was innocent, right? Wrong. I'd fed it a stage-08 mesh that had already been cleaned. Of course the cleanup didn't break an already-clean mesh. The correct test feeds the raw, pre-cleanup mesh - and when I finally did that, the sieve came right back. I'd spent real time trusting a test that I failed to set up properly.
But once the bisection harness existed, the method started paying out almost immediately - and the first two fixes it handed me were so small, and moved the needle so much, that they're worth meeting one at a time. The geometry "explosion" went from a 92.6% non-manifold catastrophe to within a hair of CUDA on the back of one keyword and one missing type-conversion call. What followed was a parade of bugs so varied and so individually plausible that each one felt like the answer right up until the next one appeared. This was a real rollercoaster of emotions, because at one point it seemed like it worked and the problem is solved, but it turned out minutes later that it was only true for a certain input or scale. Let me introduce the cast.
Bug A: the one-word cosmic horror

this is what Qwen Image 2512 had to show for this title - pretty metal
Symptom: the mesh simplifier produced a 92.6% non-manifold-edge explosion. The CUDA reference was at 5.18%. The mesh wasn't a mesh; it was 687,069 confetti charts averaging 1.31 faces each.
Cause: in simplify.metal, one buffer was declared device atomic_ulong* in the kernel that writes it, and device const ulong* in the kernel that reads it. Per the Metal Shading Language spec, this is undefined behavior - the compiler is free to cache stale reads. So the simplifier's "did my neighbor and I agree to collapse this edge?" handshake was reading stale values, two threads would both decide "yes, collapse," and they'd collapse shared-vertex edges simultaneously into topological soup.
Fix: declare the reader device const volatile ulong*. Forces a fresh load every access.
NME vertex %: 92.6% → 5.15% (CUDA: 5.18%)
Manifold edges: 41% → 98.09% (CUDA: 98.07%)
charts: 687,069 → 2,330 (CUDA: 1,731)One word. volatile. Over a week of port work and the first real win was a single keyword. I went for a long walk.
This also meant that Pedro's work might have been more buggy than I had initially thought - I started trusting it a lot less. We're all humans (and bots) after all and we make mistakes. My mistake was trusting too much that the ports were bulletproof!
Bug B: the fp32 flag that did nothing
Symptom: I had an environment variable, PIXAL3D_FP32_MODELS, that was supposed to upcast specific models to fp32. The mesh quality said it wasn't working on the DiTs.
Cause: the VAE classes expose convert_to_fp32(). The DiT classes don't - they use convert_to(dtype), and they read self.dtype (resolved to bf16 from the checkpoint filename suffix) inside every forward via manual_cast. My flag only knew how to call the VAE API, so the DiTs cheerfully stayed in bf16 while I congratulated myself for running fp32.
Fix: add a fallback - if a model lacks convert_to_fp32 but has convert_to, call convert_to(torch.float32). Now self.dtype = float32 and all those manual_cast calls become no-ops.
NME dropped 31.98% → 22.28%. Progress. A theme is emerging here: the Mac wasn't lying to me, I was lying to the Mac.
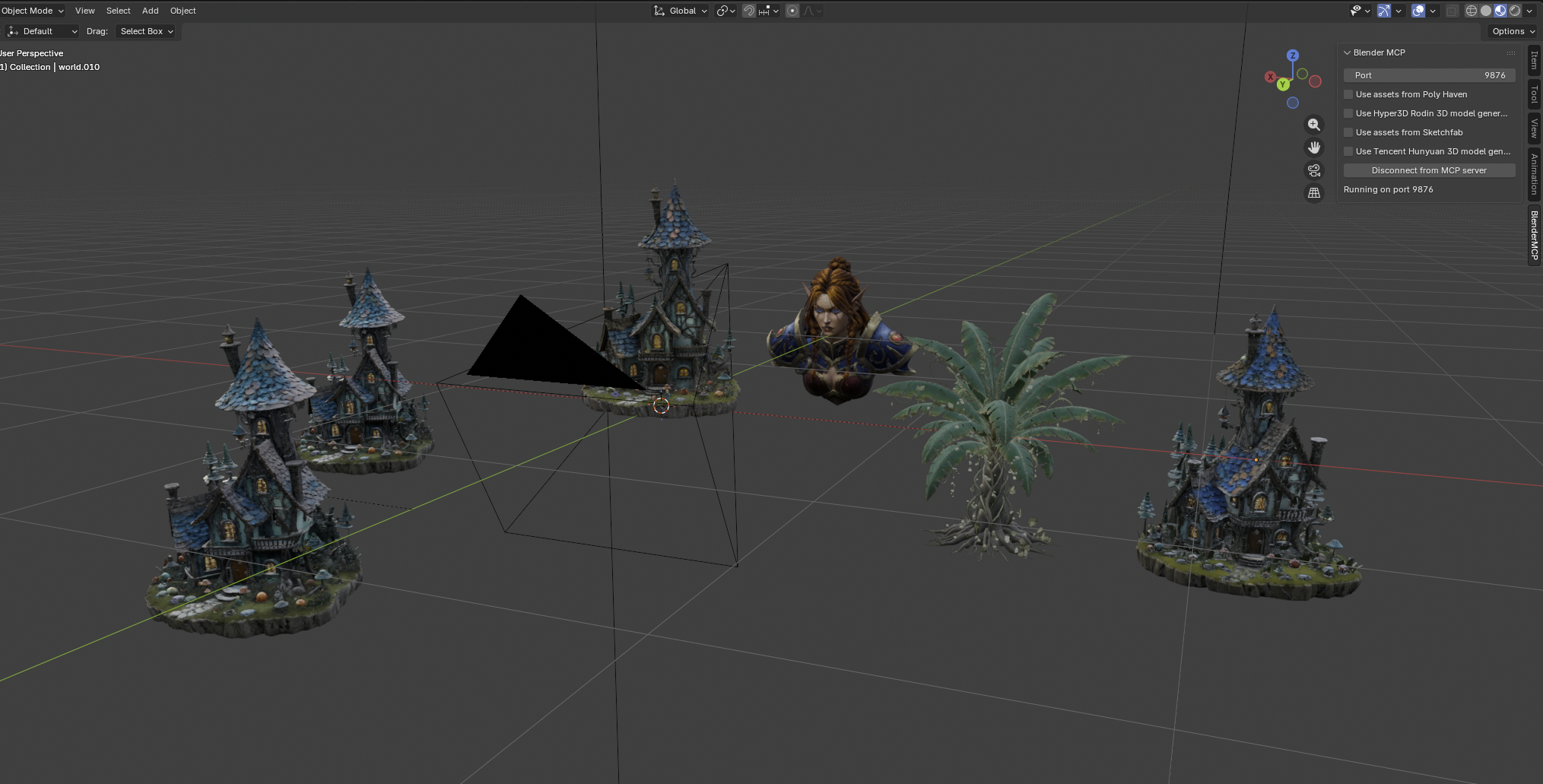
A boulevard of broken dreams (none of them were correct)
Bug C: the rasterizer that kept the back of everything
Symptom: UV-seam speckle in the texture bake.
Cause: the Metal differentiable rasterizer (mtldiffrast) was running its depth test backwards - GreaterEqual with clearDepth=0, which keeps the farthest triangle. nvdiffrast's reference rasterizer keeps the smallest z (closest). At the z=0 UV bake this turned into last-drawn-wins instead of keep-first, plus it clipped negative NDC-z.
Fix: remap the vertex z, flip GreaterEqual → Less, flip clearDepth 0 → 1, and correct the four test references that had been encoding the wrong behavior as expected output (oops). 66/66 tests pass.
Not the headline bug, but a real correctness fix - and a humbling reminder to check that your tests are testing the right thing.
Bug D: the sequence-length cliff (the big one)
Spoiler alert: that was the Holy Grail of this whole thing.
Symptom: some objects came out perfect. The turtle? Flawless. The fairy house and the robocrab? Shrunken and desaturated - the geometry physically smaller than CUDA's, the colors washed out. Same code path. Same everything. I've noticed a pattern though - the bigger the latents get, the worse are the artifacts. It was a step function.
PyTorch's MPS backend has a fused scaled_dot_product_attention kernel. Below roughly 18,000–20,000 tokens it is bit-accurate against CPU and CUDA (mean-abs error ~1e-6). At and above that threshold, it silently returns garbage - mean-abs error 0.05–0.10, with individual elements off by more than 10 on an O(1) signal. In fp32. No warning. No fallback. It just... starts being wrong.

Dude looks eaten by rust, but no rust red to be found...
Here's the kicker: the flow DiTs run sparse attention over ~21,500 tokens on the robocrab. Just past the cliff. And the turtle? Comfortably under it. That's the entire "per-object mystery" - simple meshes stay below ~18k tokens and always rendered fine, complex meshes cross the line and shatter. Every "exonerating" test I'd run on a small mesh had been testing the one regime where the bug doesn't fire. The SDPA kept passing the exam because I kept giving it the easy questions. At first I tried naively nudging values towards CUDA ground truth and it sort of worked, as the crab began to regain some of its geometry and red got somewhat back there - promising results.

Better, but not there yet. I could see though that even naively nudging attention values towards CUDA ground truth made the mesh slightly more complete and the red color returning - this was a crucial clue.
It quickly became clear that the bug is clearly there and that values are not what they should be, but this naive approach was not the way to go, it was only useful as a diagnostic. So the idea at first was to migrate these attention calculations to CPU to see if the numbers match with CUDA. Lo and behold - it did. But I don't want CPU! I have this pretty strong GPU in this machine and I'd like it used thank you very much. So the next test was to use MPS, but instead of using built-in PyTorch fused kernel for SDPA, hand roll one myself and then use it naively - each step at a time. Aaaaand.... it worked! The numbers matched! What a joy!
Because attention sits inside a 30-block residual stack, the per-call error compounds. One slightly-wrong attention output, thirty times over, becomes the "variance collapse" that shrank the geometry and drained the color:
Single HR-DiT forward (identical noise + cond):
CUDA 1.24633
CPU fp32 1.24629
MPS fused 1.07553 ← the lone outlier
MPS (fixed) 1.24676
HR shape-latent std: CUDA 5.63 / MPS-broken 4.99 / MPS-fixed 5.67
Robocrab saturation: broken 0.139 → fixed 0.341
Proof it's the kernel and not my code, precision, or reduction order: I wrote a self-contained 40-line repro with random q/k/v and no Pixal3D at all. Bit-exact through N=18000, breaks at N≥20000. A mathematically identical manual matmul → softmax → matmul on the same MPS device stays bit-accurate at every N. So MPS matmul is fine. MPS softmax is fine. Only the fused kernel is haunted for some reason.
Fix: a naive attention backend that computes attention as a chunked (2048-query) fp32 matmul → softmax → matmul. The chunking isn't optional, by the way - the full [B, H, N, N] score matrix is about 22 GB at N=21500, and that allocation also fails on MPS. So even the workaround needed a workaround.
I was under impression for a second that I have found a bug in PyTorch. And boy, I did! I just wasn't the first one to do it - it got written up as a proper upstream bug report (https://github.com/pytorch/pytorch/issues/179352 - still not fixed in the upstream at the time of this writing).
This bug almost certainly affects every TRELLIS-family Apple Silicon port using long-sequence sparse attention (probably the reason for low quality of Trellis-mac outputs), but not only that - lot of models that originally depend on flex attention turns to SDPA when running on Mac - the PyTorch bug filed upstream showed up when somebody was doing some video generation locally.
If you take one thing from this post is that sometimes even things that you'd think obviously are not wrong (I mean why wouldn't I trust upstream PyTorch implementation of SDPA) are worth instrumenting and checking against real results at different scales.
Bugs E & F: the remesh was fine, actually - it was the thing under the remesh

Poor bastard lost his hair.
After Bug D, the geometry was the right size and the color was back. But the high-detail regions - the fairy's little pumpkins and mushrooms, the sword inlay, the orc's hairline - were still shredded, with an atlas that exploded to 30,000–100,000 charts where CUDA had a tidy ~1,700. Which was disappointing - because I was really hopeful that last one will be IT.
Diagnosis (the E part): the CUDA reference pipeline always bakes with to_glb(remesh=True), which runs a narrow-band dual-contouring remesh that rebuilds a watertight manifold. The Mac pipeline was running remesh=False and falling back to a "simplify-sieve" branch that is intrinsically holey (~8–11% open boundary) on dense thin-feature meshes - on both Mac and CUDA. The fix seemed obvious: turn on remesh=True. Except the Metal remesh produced an 8.78%-boundary, 18,636-component disaster. So the remesh was off because the remesh was broken.
A crucial measurement detour here: I'd been counting connected components on the indexed vertices and concluding the Mac mesh was ~3× more fragmented. Wrong metric. Texture baking duplicates vertices along every UV seam, inflating component counts 3–10×. Switch to coordinate-welded metrics (round vertices to 1e-6, then count) and the truth appears: CUDA's out.glb is 0.0% boundary (genuinely watertight); the Mac mesh was 10.7%. Always make sure you count the right thing guys.


I have no mouth and I must scream vibe
Root cause (the F part): I cross-baked - ran the same mesh through the Mac geometry kernels and the CUDA ones - and they matched step for step. The simplify/repair/small-cc kernels were faithful. The corruption was happening one layer down, inmtlbvh, the BVH that computes the unsigned distance field the remesh contours against. Queried exactly at a mesh vertex (where distance must be ~0), it returned mean 0.002, max 0.011, and exceeded the nearest-vertex distance for 53% of near-surface queries - which is physically impossible for a correct distance field.
And the final piece of the puzzle turned out to be a struct named FixedStack24:
void push(...) { if (count < 24) { ... } } // silently drops everything past 24The BVH traversal stack was capped at 24 entries, and push silently dropped anything beyond that. The tree is 4-ary and pushes up to 4 children per node, so peak stack occupancy is roughly 3 × depth + 1. On the 1,280-face test sphere, depth is tiny - never overflows, always correct. On the real 8.6-million-face decoded mesh, depth is ~11–15, needing ~34–46 slots. Overflow. Whole subtrees skipped. Nearest triangle missed. Distance over-estimated. Remesh corrupted.
Fix: FixedStack24 → FixedStack64. That's it. The size-dependence is the whole story - every test on a small mesh said the BVH was perfect, because on small meshes it was.
At-vertex distance: 0.002 → 0.000001
Over-estimate rate: 53% → 0%
Remesh boundary: 8.03% → 0.00% (15,150 comps → 565)
Final baked GLB: 0.06% boundary, largest body 0.974
(CUDA out.glb: 0.0%, 0.978)Confetti → CUDA-quality. --native-remesh is now the default.
There's a pattern across Bugs A, D, and F that I want to name explicitly, because it cost me many days: every one of them was invisible at small scale. The cliff at 18k tokens, the stack overflow at deep trees, the race that only fires under enough parallel collapses. Your unit tests pass. Your small repro passes. And the bug is sitting there the whole time, waiting for a mesh big enough to ruin your day.
Bug G: the kernel that ate the WindowServer
While in the BVH neighborhood, I noticed every linear-probing loop in the Metal hash kernels was an unbounded while(true). On a GPU - where the host is blocked on waitUntilCompleted - any non-terminating probe (a full hash chain, garbage coordinates, N==0) wedges the GPU, which crashes the WindowServer, which thermally locks the whole machine. I know this because it happened to me. Once. Mid-session. My Mac just... hang. ~ Remembering the Windows days ~ I had to properly kill it. Thankfully it turned back on - for a second I thought it might be mad at me for doing such a silly thing to it.
Fix: bound every probe loop to ≤ N (a correct table always resolves within N anyway, so behavior is unchanged), guard N==0, and - bonus correctness bug - stop advancing the probe on spurious atomic_compare_exchange_weak failures. MSL only gives you the weak CAS, which can fail on an empty slot for no reason; the original code treated that as "occupied" and skipped ahead, leaving a gap in the chain that lookups would miss. Retry the same slot instead. CUDA gets to use a strong atomicCAS and never has this problem. We are not so lucky.
Bug H: the one where it was secretly fine the whole time
Symptom: Mac GLBs looked "chunky" and faceted in viewers, like a low-poly aesthetic nobody asked for.

Cause: the GLBs had no NORMAL accessor at all (CUDA's had 787,900), so every glTF viewer fell back to flat per-face shading. The pipeline computes perfectly good smooth normals - but trimesh's exporter silently drops them unless you pass include_normals=True.
Fix: pass include_normals=True. The GLB grew from 31.4 MB to 41.8 MB (CUDA: 44.4 MB) and started rendering smooth. After eight bugs of "the Mac is computing the wrong thing," it was almost relaxing to find one where the Mac computed the right thing and then threw it in the bin on the way out the door.
And when the confetti settled...
For every fix that shipped, there's a small graveyard of work that didn't. I built an entire texturing pipeline out of Blender and KDTree baking and then deleted it. I chased conditioning drift through the Neural Engine for three sessions to close a number that turned out not to matter. I ported cumesh's QEM simplifier to CPU by hand - pamo_simplify.py, phases 0 through 7 - only to prove the Metal port had been faithful all along and mine was just slower. I wrote a standalone Metal NAF encoder and a Metal natten port, validated both to the fp32 noise floor, and shipped neither as a fix (they change nothing measurable - they just exist as cleaner substrate). I swept decimators I'd rather not meet again - fast_simplification, pymeshlab, Blender Decimate-Collapse, voxel remesh - and tuned fill_holes perimeters and small_cc thresholds into combinations that scored better on every metric and looked worse to every human. I added env-var levers (PIXAL3D_SUBDIV_BIAS, PIXAL3D_FP32_ATTN) that turned out to be perfect no-ops, kept in the tree for honesty's sake. And I burned real money renting NVIDIA GPUs to generate reference tensors for theories I then had to abandon. None of it was wasted, exactly - every dead end deleted a hypothesis, and the real bug was always hiding behind the one I hadn't killed yet - but it's only honest to admit the two-week "port" was maybe 20% writing the code that shipped and 80% proving which code didn't need to.
Final score: eight named bugs, A through H, spread across Metal shaders, a PyTorch backend kernel, a BVH traversal, a depth test, an export flag, and my own configuration plumbing. The Mac now produces watertight, CUDA-comparable, smoothly-shaded fairy houses. --native-remesh is on by default, the attention runs the chunked naive backend, and the metallibs rebuild from a script.
Three things I'd hand to anyone starting a port like this:
Build the bisection harness before you fix anything. "The first stage with a non-trivial diff is the bug boundary; everything after is consequence, not cause." That framing converts an unsolvable blob into a sequence of solvable problems.
Distrust every test that passes on a small input. Three of my worst bugs - the SDPA cliff, the BVH stack overflow, the simplify race - were completely invisible below some scale threshold. If your repro is small enough to be convenient, it's small enough to be lying.
Search for an existing community port before you write a kernel from scratch. This one I learned the hard way and have since tattooed onto my project memory: check PyPI, check GitHub topics (
apple-silicon,mps,metal), check everything. The Apple Silicon ecosystem is growing fast, and someone may have already suffered so you don't have to. (Sometimes they have, and it's worse - the MLX community port produced more artifacts than the MPS path - but you want to know that, not guess it.)
And I don't know - maybe it was trivial stuff for somebody more knowledgeable and would be much easier and less time consuming than for ignorant like me, but nobody did, so I took this opportunity to get this done.
I can't tell you how happy I am with the result.
It took me a lot of work to get to this point. Worth it. The fairy house looks great.
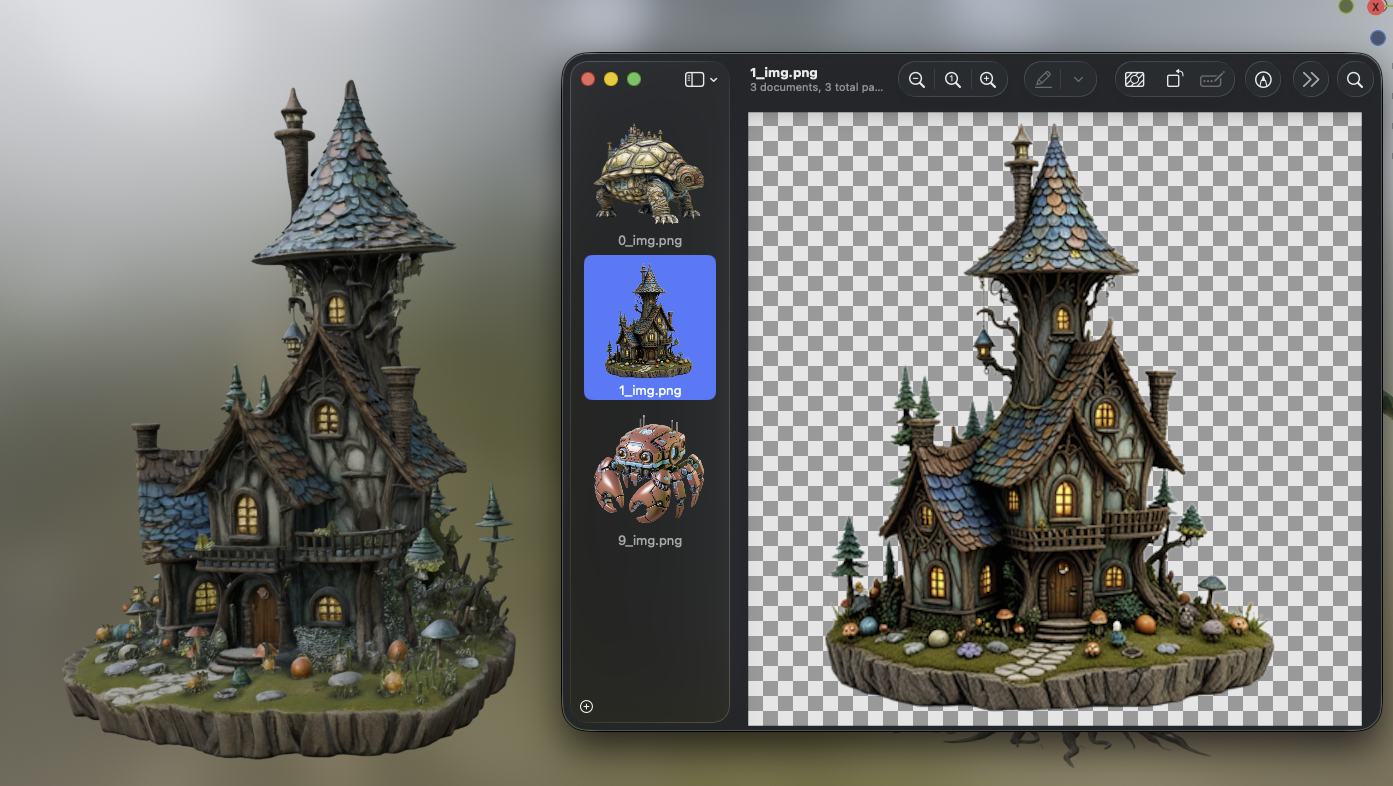
- written from the feat/apple-silicon-port branch, where the confetti has finally settled.
Extra evals:
Bonus (the filenames are the ones that are actually in original Pixal3D repo under assets/images):
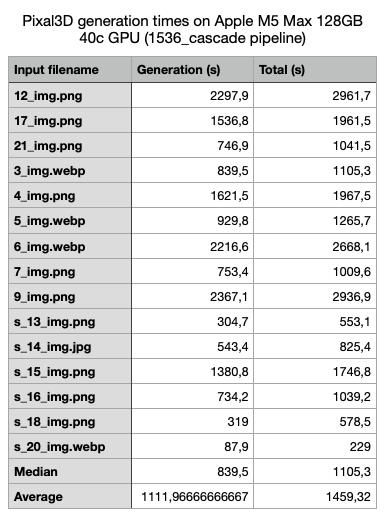
Where "Generation" is for mesh only (no texture) and total is for mesh generation + texture baking.
For the really, really curious ones, there's: https://github.com/pawel-mazurkiewicz/Pixal3D-mac/blob/master/PIPELINE_MAP.md
Acknowledgements and thanks:
- original Pixal3D team from TencentARC (https://github.com/TencentARC/Pixal3D) for training this model and doing research for it in the first place
- Shivam Kumar and his Trellis-mac (https://github.com/shivampkumar/trellis-mac) - for doing it and making me believe it's not stupid to try
- Pedro Naugusto (https://github.com/pedronaugusto) - for his work on CUDA stack rewrites to Metal- TRELLIS2 from Microsoft (https://github.com/microsoft/TRELLIS.2) - as the one that helped start the others, like Pixal3D
Next stop: Khala audio!